
Come descritto nel primo articolo, uno degli obiettivi che mi sono prefisso è quello di rendere facile la comprensione di argomenti che richiedono conoscenze tecniche e scientifiche a chi magari non è del settore. Questo perché come ho già detto, credo che nel 2018 in un mondo dominato dall’elettronica e dall’informatica, non possiamo subire il progresso e le nuove tecnologie senza conoscere almeno i principi che stanno alla base del loro funzionamento.
Per fare questo dovrò affrontare concetti ed argomenti secondo un filo logico cercando di collegarli tra loro, in modo da rendere ogni articolo propedeutico per i successivi.
Una volta affrontati tutti gli argomenti che ritengo basilari, potremo addentrarci maggiormente nelle nuove scoperte tecnologiche, andando magari a capire il funzionamento della rete internet, di un PC, del GPS, o di altre importanti scoperte che da circa 30 anni stanno condizionando la nostra vita quotidiana.
Anche se il linguaggio utilizzato finora è abbastanza semplice ed elementare, sono sicuro però che l’approccio molto elementare potrà essere utile anche ai più “esperti” che, anche se conoscitori della tecnologia, a volte sono carenti proprio negli aspetti basilari, perché magari provenienti da una formazione più recente o troppo “settoriale” che non sempre riesce a fornire le conoscenze che stanno alla base dell’informatica e dell’elettronica.
Non voglio ovviamente sminuire nessuno, ma è normale che chi ha vissuto la crescita tecnologica in tutti i suoi passaggi e da diverse angolature, ha avuto modo di affrontare problematiche diverse magari più legate all’elettronica, o situazioni che oggi non esistono più, basti pensare all’utilizzo della shell dei comandi (cioè quella schermata nera dove si digitavano i comandi da impartire al PC) oggi non più presente in diversi sistemi operativi in quanto dotati della sola interfaccia grafica.
Comunque dopo questa doverosa premessa andiamo ad affrontare il terzo aspetto legato al mondo del digitale e cioè il funzionamento di un microprocessore.
Dopo aver spiegato la differenza tra analogico e digitale ed aver fatto capire in che modo i numeri vengono trattati, andiamo a vedere come questi numeri vengono interpretati e letti dal cervello delle nostre macchine e cioè il microprocessore.

In precedenza ho nominato un dispositivo diverso e cioè il microcontrollore, che altro non è che un evoluzione del microprocessore, anzi direi più esattamente che è un microprocessore contenente memorie ed altri circuiti che lo rendono simile ad un piccolo PC.
Ma se vogliamo capire come i numeri vengono interpretati ed elaborati conviene partire dal microprocessore e cioè quel dispositivo che troviamo dentro al nostro PC e che elabora i dati tramite i programmi che noi scegliamo di mandare in esecuzione.
La parola “microprocessore” da l’idea del componente, infatti è “micro” nel senso di piccolo, ed è un “processore” perché in grado di “processare” (nel senso di sottoporre ad analisi) dei dati e delle informazioni.
Ma come avviene tutto questo? Come può un componente leggere un numero ed eseguire un’istruzione?
Per spiegare il funzionamento in maniera approfondita occorrono conoscenze molto ma molto complesse per i “non addetti ai lavori”, ma ragionando con analogie e con semplici esempi spero di riuscire a descrivere almeno il “modus operandi” di questo cervello elettronico.
Forse è esagerato chiamarlo cervello, anzi togliamo pure il forse, perché il nostro cervello ha delle caratteristiche che una macchina non potrà mai avere (almeno per ora) e poi come scrivo nel titolo, gli aggettivi più giusti da utilizzare sono proprio “stupido” e “veloce“.
E’ stupido perché riesce a comprendere solo il sistema binario (quello descritto nel precedente articolo) composto solo da due cifre 0 ed 1. Questo perché nel suo DNA c’è la sola capacità di riconoscere il si dal no, il nero dal bianco, il bello dal brutto, non ci sono vie di mezzo o una cosa è vera o è falsa. Ma vicina a questa caratteristica ce ne è un’altra che lo rende molto potente e cioè la velocità. Ebbene si un microprocessore è in grado di svolgere semplici operazioni ma ad una velocità di “ragionamento” che noi ci sogniamo. Un moderno processore del PC o del nostro telefonino ha una velocità (Clock) di circa 2 GHz, cioè 2 miliardi di Hertz, questo è il battito del suo cuore, ed è come se battesse 2 miliardi di volte al secondo, regolando con questo ritmo la velocità delle sue azioni. Ad esempio un processore comunemente utilizzato oggi nei nostri PC l’Intel I5 con 2GHz di clock riesce ad eseguire 60 milioni di istruzioni al secondo (60 MIPS).
Perciò la sua “poca intelligenza” viene aiutata enormemente dalla sua “sorprendente velocità“. Ma come fa il microprocessore a leggere ed elaborare i dati?
Era il 1986, quando per la prima volta vidi un nanocomputer, questo era un dispositivo didattico con dentro un microprocessore chiamato Z80, era lo stesso processore presente nello “Spectrum” uno degli antenati delle moderne consolle per videogiochi playstation, xbox, wii ecc….


In questo nanocomputer erano presenti diversi componenti elettronici, c’era il microprocessore, c’erano delle memorie RAM (memorie che perdono il loro contenuto quando la macchina viene spenta) delle memorie EPROM (memorie che mantengono i dati anche se la macchina viene spenta) un display, un tastiera con numeri e qualche lettera ed altri componenti elettronici.
Il nanocomputer era un semplice PC con funzioni minimali, ma il suo utilizzo rendeva comprensibile il funzionamento del microprocessore Z80.
Cominciamo a ragionare partendo dai bit descritti nel precedente articolo. Chi non l’ha fatto può leggerlo ed arrivare così alla conclusione che tutti i numeri si possono rappresentare con il sistema binario, cioè una sequenza di bit che possono valere 0 o 1. Un insieme di 8 bit viene definito byte ed indicato con la lettera B. Lo Z80 riusciva a leggere 8 bit per volta, ma dove li leggeva questi bit e cosa significavano per lui?
Cominciamo dalla prima domanda, dove venivano letti i numeri. Ogni microprocessore legge i miliardi di bit da una memoria. Ci sono diversi tipi di memorie, ci sono quelle magnetiche descritte nel precedente articolo, dove il bit 0 o 1 rappresenta una piccola parte di un disco magnetico (0 se non è magnetizzato 1 se lo è). Ci sono le memorie ottiche, dove con un raggio laser si rileva la presenza o l’assenza di una zona piana in rilievo sulla traccia del disco (anche in questo caso 0 o 1) ci sono poi le memorie elettroniche che sono quelle presenti nel nanocomputer o nei moderni computer. Di sicuro sulle memorie e sul funzionamento dei vari dispositivi di memorizzazione scriverò quanto prima un articolo, ma per ora possiamo considerarle genericamente come un dispositivo che contiene internamente milioni anzi miliardi di bit.
Per semplicità consideriamo una memoria elettronica come una cassettiera con dei cassetti contenenti internamente degli scomparti, che a loro volta contengono il singolo bit.
Ogni cassetto viene indicato con un numero progressivo sempre esclusivamente in binario, ed ogni cassetto contiene un numero di bit ben definito, che nel caso delle memorie del nanocomputer è di 8 bit.
La struttura di una memoria perciò potrà essere schematizzata in maniera semplificata nel seguente modo.
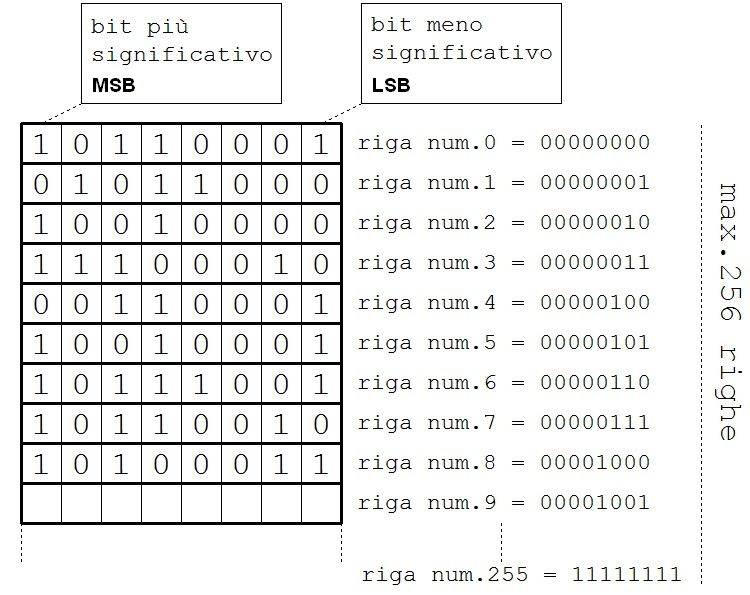
In pratica nella figura è come se avessimo una cassettiera con 256 cassetti (righe) contenenti 8 bit ogni cassetto.
La quantità di righe dipende da quanti bit vengono utilizzati dal microprocessore per scegliere il “cassetto” e nella figura ho ipotizzato 8 bit. Il contenuto di ogni cassetto è invece un numero, ed esso può rappresentare un valore, o il codice di un’istruzione da eseguire.
Il valore ad 8 bit letto dalla memoria va a finire in un’altra piccola memoria interna al microprocessore, chiamata registro, in genere i registri sono più di uno, ed il più importante è il registro chiamato “accumulatore“.
Una volta che gli 8 bit vengono letti dalla memoria si procede alla fase di decodifica dell’istruzione dove il microprocessore attraverso la sua struttura circuitale interna, compara il codice letto con una delle istruzioni possibili.
Ogni microprocessore ha infatti il proprio “set di istruzioni” e cioè l’insieme delle istruzioni che può eseguire. Nel caso dello Z80 in tutto ci sono circa 200 istruzioni codificate con dei numeri scritti in binario. Sono in genere operazioni semplici, come incrementare o decrementare un valore di un unità, o ruotare gli 8 bit letti dalla memoria a destra o a sinistra, o sommare due valori e così via.
Ogni istruzione ha un corrispondente codice binario, ad esempio se nella riga di memoria il microprocessore trova il codice binario 00111100 equivale a dire di incrementare di un’unità il contenuto del registro accumulatore, oppure se trova scritto il valore 11000011 vuol dire che dovrà leggere ed eseguire il codice contenuto nella riga della memoria indicata nei prossimi due byte.
Bisogna considerare che all’accensione il microprocessore si posiziona alla prima riga della memoria, la legge esegue l’istruzione assegnata e prosegue passando per le righe successive. Ci sono anche delle istruzioni che dicono al processore di continuare a leggere più avanti nella memoria (salti). Per essere più chiari faccio un esempio di 3 istruzioni consecutive, cerchiamo perciò di prestare la massima attenzione alla seguente figura ed alla spiegazione successiva.
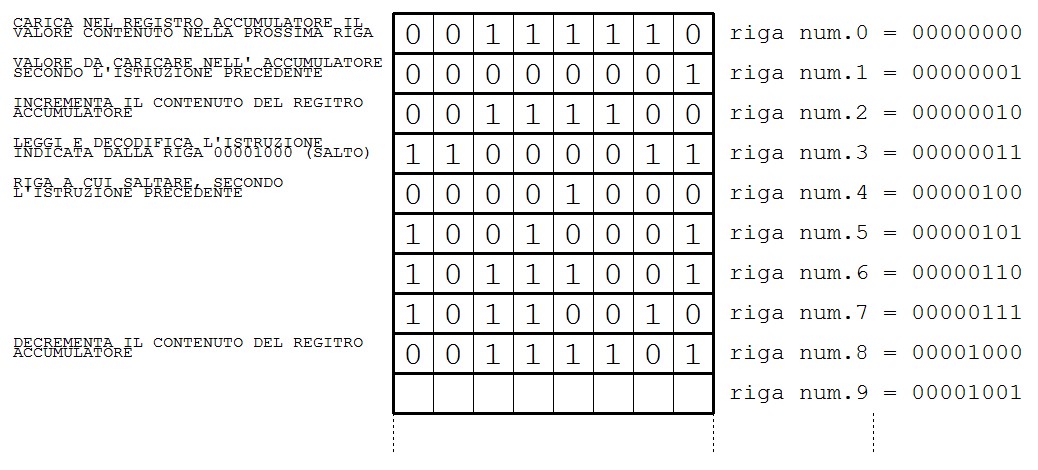
Poniamo il caso che qualcuno scriva nella memoria i numeri binari come indicato nella figura precedente, andiamo a vedere come si comporterebbe il microprocessore.
- all’accensione il microprocessore legge la riga della memoria 00000000 e trova il valore binario 00111100
- decodifica questo codice e riconosce l’istruzione LD A , che significa carica (cioè scrivi) nell’accumulatore un numero (LD sta per load)
- successivamente il microprocessore legge la seconda riga dalla memoria identificata con ooooooo1 e trova il valore 00000001, che rappresenta il valore che dovrà mettere nel registro accumulatore secondo quanto richiesto dalla precedente istruzione. In questo caso sono servite due righe di memoria per dire al microprocessore cosa fare.
- a questo punto il microprocessore dopo aver caricato nell’accumulatore il valore 00000001, prosegue e legge dalla riga della memoria successiva identificata con 00000010. Trova il codice binario 00111100, lo decodifica e lo riconosce come l’istruzione INC A , cioè “incrementa il contenuto dell’accumulatore”, a questo punto il microprocessore eseguirà l’istruzione portando il registro accumulatore al valore 00000010 (2 in decimale). In questo caso è stata sufficiente una sola riga della memoria per indicare l’operazione da fare.
- poi viene letta la riga successiva dalla memoria che è quella identificata dal codice 00000011. Qui il microprocessore trova il codice binario 11000011 e riconosce questo codice come un salto. In pratica gli viene detto di continuare a leggere da un’altra zona della memoria e cioè quella identificata dal numero contenuto nel prossimo byte cioè 00001000
- a questo punto il microprocessore si porterà a questa riga ed eseguirà l’istruzione identificata dal codice contenuto che è quella di decrementare il contenuto dell’accumulatore.
Ho semplificato un po’ (anzi tantissimo) la questione e modificato anche una delle istruzioni, ma quello che accade è proprio questo.
Lo stupido microprocessore si limita infatti a leggere da una memoria dei numeri in binario e li decodifica secondo un insieme di istruzioni predefinito a lui noto, nulla di più. Ma visto che riesce a fare tutto questo in maniera davvero rapida e veloce, si possono combinare le istruzioni per realizzare delle operazioni più complesse e dei programmi di qualsiasi tipologia.
Nel caso del nanocomputer il programma veniva scritto riempiendo le celle della memoria (quelle che abbiamo finora, erroneamente ma per semplicità, chiamato righe) con dei valori manualmente e successivamente si mandava in esecuzione il programma in modo da ottenere il risultato richiesto. E’ ovvio che i programmi erano molto semplici ma con un po’ di pazienza e con il set delle istruzioni sempre davanti, si potevano scrivere anche programmi un pochino più complessi.
Nel nanocomputer il microprocessore era ovviamente collegato elettricamente alle memorie e ciò avveniva secondo un insieme di contatti definito BUS. C’è il BUS dati che nel caso dello Z80 è un insieme di 8 collegamenti che collega la riga della memoria selezionata con il microprocessore, c’è il BUS indirizzi che nello Z80 è composto da 16 collegamenti che collega sempre la memoria con il microprocessore, e che consente di scegliere quale riga leggere o scrivere, poi c’è il BUS di controllo dove transitano altri collegamenti che definiscono il tipo di operazione che si vuole fare, ad esempio se si vuole leggere o scrivere il valore. In tutti i casi il bit rappresenta un segnale elettrico, ed esattamente il valore 0 identifica un segnale elettrico nullo ed il valore 1 la presenza di un segnale elettrico di un determinato valore.
Il programma di esempio visto prima non serve assolutamente a nulla, era solo un piccolo esempio, ma nella realtà tutti i microprocessori, anche i più nuovi e potenti leggono dei bit e li decodificano. Ovviamente il programmatore non scrive il programma inserendo nella memoria i singoli bit che rappresentano il “codice macchina“, ma scrive il programma in un linguaggio più comprensibile all’uomo.
Cerchiamo allora di fare chiarezza anche in questo campo e cioè il linguaggio. Il linguaggio macchina è quello composto da codici binari è unico e dipende solo dal microprocessore. Ognuno ha un suo set di istruzioni diverso con più o meno istruzioni ad esempio i processori dei telefonini sono costruiti con una tecnologia di tipo RISC (Reduced Instruction Set Computer) che tradotto significa set di istruzioni ridotto. In pratica ci sono meno istruzioni di un normale microprocessore per computer, ma di fatto si riescono comunque a fare le stesse cose.
Poi c’è il linguaggio assembly dove l’istruzione non viene codificata con un numero binario, ma con una dicitura mnemonica più comprensibile al programmatore. Nell’esempio visto prima il codice assembly dell’istruzione “incrementa il contenuto dell’accumulatore”, era INC A , ed il codice macchina corrispondente era 00111100.
“Incrementare il contenuto del registro accumulatore” = INC A = 00111100
In pratica la stessa istruzione può essere descritta con un codice comprensibile al microprocessore o con una sintassi comprensibile al programmatore. Se il programmatore scrivesse un programma in linguaggio assembly, servirebbe qualcuno per tradurlo in codice macchina e (a meno che non ci sia un volontario che leggendo il set delle istruzioni lo faccia manualmente riga dopo riga) lo si può fare con un apposito programma chiamato assemblatore o assembler. Perciò un programmatore potrebbe scrivere il programma tramite il conosciuto “notepad” o un qualsiasi editor e poi darlo in pasto al programma assemblatore che si occupa di creare il file binario comprensibile dal microcontrollore.
Fino ad ora abbiamo però ragionato ad un livello molto vicino alla macchina, perché di fatto anche l’assembly pur se non comprensibile dal microcontrollore, è molto vicino al linguaggio macchina e per questo più difficile da comprendere per il programmatore. Il programmatore è una persona e come tale ha bisogno di istruzioni che possa ricordare (perciò un linguaggio mnemonico) ed ha bisogno di istruzioni che facciano qualcosa di più difficile che il semplice incremento di un valore. Ed è per questo motivo che sono nati i linguaggi di programmazione, che altro non sono che un insieme di istruzioni e di operazioni più vicine e comprensibili all’uomo che alla macchina. E non solo, con i linguaggi di programmazione anche la gestione dei registri interni al microprocessore non viene più gestita dal programmatore.
Il programmatore non farà altro che scrivere i nomi delle variabili che vuole utilizzare (per variabile intendiamo un contenitore di numeri ed altri dati) ed eseguire l’operazione di cui ha bisogno. Pensiamo ad esempio al linguaggio C uno dei più conosciuti, se volessimo fare una moltiplicazione tra due numeri interi sarebbe sufficiente scrivere quanto segue:
int numero1,numero2;
int risultato;
void main() {
numero1=5;
numero2=3;
risultato=numero1*numero2;
}
Come si può notare non mi sono interessato della riga di memoria da leggere o del suo contenuto, ma ho solo scritto in sequenza quello di cui avevo bisogno cioè; 3 variabili che possano contenere dei numeri interi (int) che ho chiamato numero1, numero2 e risultato e le 3 operazioni da fare che sono caricare i due valori da moltiplicare ed eseguire poi la moltiplicazione. Il tutto l’ho scritto dopo l’identificazione dell’inizio del programma che è la dicitura void main().
Se avessi scritto lo stesso programma in assembly avrei avuto bisogno di una ventina di righe o forse più, ma soprattutto avrei avuto bisogno di spiegare cosa stavo facendo, cosa invece inutile nelle 3 righe di programma scritto in linguaggio C.
Ma se scrivo un programma in qualsiasi linguaggio come faccio poi a trasformarlo in linguaggio macchina? Anche in questo caso mi viene in aiuto un software chiamato “compilatore“, che non fa altro che trasformare ciò che ho scritto prima in assembly e successivamente in linguaggio macchina.
Oggi i linguaggi di programmazione sono tantissimi, dai più vicini al modo di ragionare della macchina, a quelli con un livello di astrazione più alto che consentono al programmatore di sviluppare agevolmente qualsiasi programma in maniera veloce e magari utilizzando altre parti di codice già scritte. In ogni caso però c’è sempre un compilatore che trasforma ciò che abbiamo scritto in una sequenza di bit 0 ed 1 che rappresentano il linguaggio macchina del microprocessore, che è sempre composto da tantissime istruzioni elementari che il microprocessore eseguirà ad una velocità elevatissima.
Spero di essere riuscito a gettare le basi di un argomento su cui probabilmente ritorneremo in altre occasioni magari con un approccio un po’ più avanzato.
Grazie.